一个在 GitHub 上疯传的 AI 助手
2026年初,OpenClaw 在 GitHub 狂揽 10万+ Star 彻底出圈。
你可能在朋友圈、技术群、或者各种社交媒体上见过它。有人说它是"长了手的 Claude",有人用它处理保险理赔纠纷,有人让它代替自己谈判、安排日程,甚至全权处理一些日常事务。
今天不谈安装,只谈架构。仔细研究 OpenClaw 的架构,你会发现 OpenClaw 其实是个绝佳的"教科书"——它把当下所有主流 AI Agent 的核心设计模式,都用最直白的方式展现了出来。看懂了 OpenClaw,你就看懂了 AI Agent 的底层逻辑。
先说清楚:OpenClaw 到底是个啥?
很多人第一次听说 OpenClaw,以为它是个聊天机器人。错了。
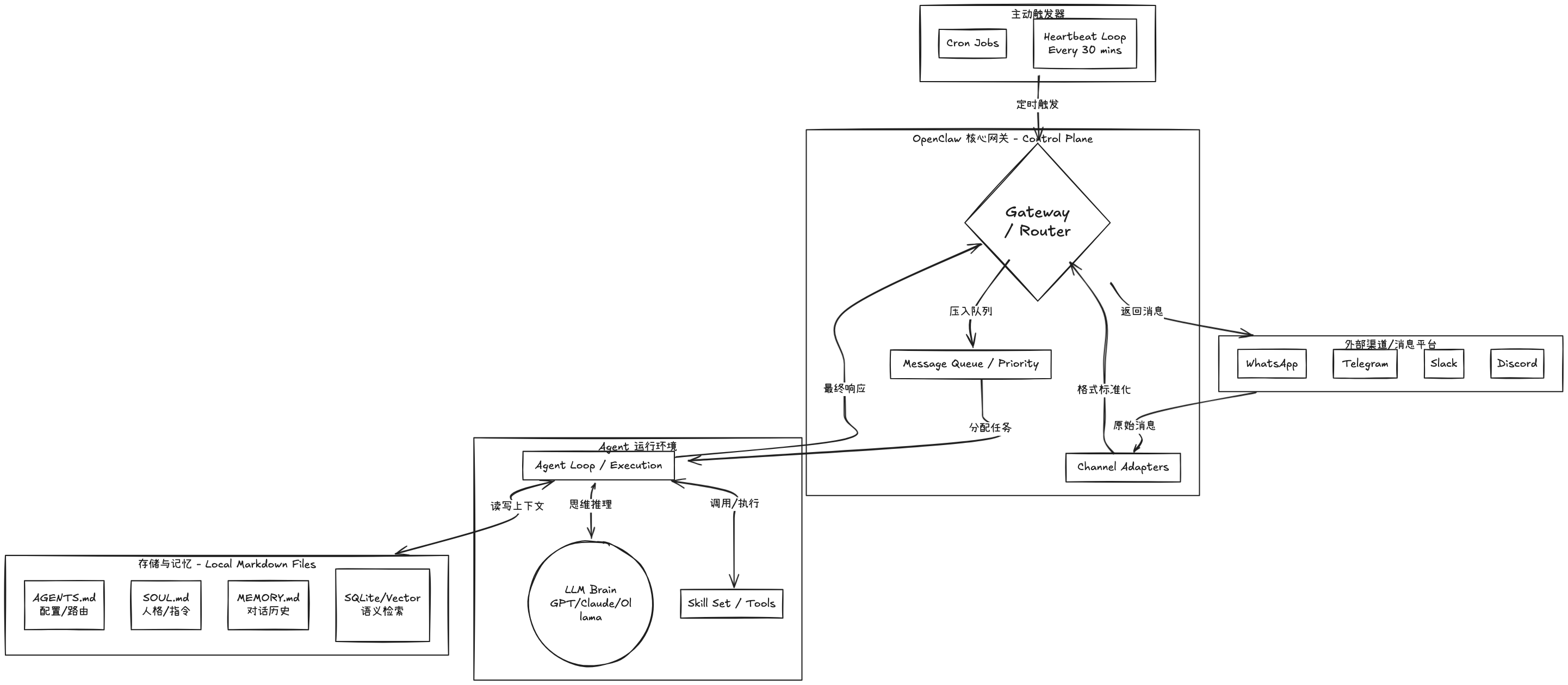
OpenClaw 本质上是一个运行在你本地电脑(或服务器)上的网关程序。它连接你日常用的各种聊天工具——微信、飞书、Telegram、Slack——然后把每一条发给它的消息,都交给一个 AI 大模型来处理。
大模型你可以用 Claude、GPT、Gemini,甚至完全本地运行的开源模型。OpenClaw 不挑模型,你用什么都行。
关键是,这个 AI 不只会回复文字,它还能真的去做事:读写文件、执行命令、发邮件、浏览网页、管理日历……
表面上看,它像个智能助手。
往深了看,它其实是一个 AI Agent 的本地编排平台。
这个区别很重要——智能助手是"你问我答",而 Agent 编排平台是"你让我做事,我想办法搞定"。这也是我们接下来要拆解的核心。
第一层:网关——整个系统的"神经中枢"
OpenClaw 的所有操作,都要经过一个叫 Gateway(网关)的进程。Gateway 简单的说就是个调度器,负责路由和分发。比如你做公交车,人很多,车很多,你就需要一个调度中心去管理那些人做什么车去什么方向。官方文档把它称为"唯一的真相来源",负责会话管理、消息路由、渠道连接。
这个网关通常作为后台服务常驻运行。
它一头连接你日常用的各种聊天工具——微信、飞书、Telegram、Slack——然后把每一条发给它的消息,统一格式。
一头连着 Agent Runtime,把各个渠道收到的消息发送给 Agent,如果消息非常多,它会建一个消息队列,排好队一个一个处理。
真正的 AI Agent 部署,永远不会把大模型 API 直接暴露给用户输入。你得在中间放一个受控的编排层,负责路由、排队、状态管理。OpenClaw 把这个模式做得清清楚楚。
第二层:输入标准化——让不同平台"说同一种话"
当你在微信上给 OpenClaw 发条消息,第一件事不是调用 AI,而是先经过一个渠道适配器(Channel Adapter)。
OpenClaw 支持十几种聊天平台,每个平台的协议和消息格式都不一样。微信的语音消息和 Slack 的文本消息,数据结构完全不同。
微信/飞书
语音消息转文字、群聊/私聊区分、消息类型统一
Telegram/Slack
Markdown 解析、Bot 指令识别、频道上下文
渠道适配器的工作,就是把这些五花八门的输入,统一转换成一个标准的消息对象:发送者、内容、附件、渠道信息。如果你发的是语音,它会先转成文字,再往下传。
在大模型看到输入之前,先把它标准化。为什么?因为你喂给大模型的上下文,决定了它的输出质量。输入乱七八糟,输出就会一塌糊涂。
第三层:路由和会话——谁来处理?处理到哪一步了?
网关拿到标准化的消息后,要决定两件事:
- 交给哪个 Agent 处理?
- 这条消息属于哪个对话?
OpenClaw 支持多 Agent 路由。你可以给不同的渠道、联系人、群组配置不同的 Agent。比如:
- 私聊用一个 Agent,语气随意,能访问你的日历
- 工作群用另一个 Agent,正式一点,能查产品文档
所有这些,都通过同一个网关进程管理。
每个 Agent 维护自己的会话(Session):一个有状态的对话记录。会话有 ID,记录历史,而且——注意这个细节——同一个会话的消息是串行处理的,不是并发的。
当 Agent 共享状态时,并发是危险的。按会话串行执行,是个深思熟虑的设计决策,不是性能妥协。官方文档说得很明白:串行化可以防止工具冲突,保持会话历史一致。
核心:Agentic Loop
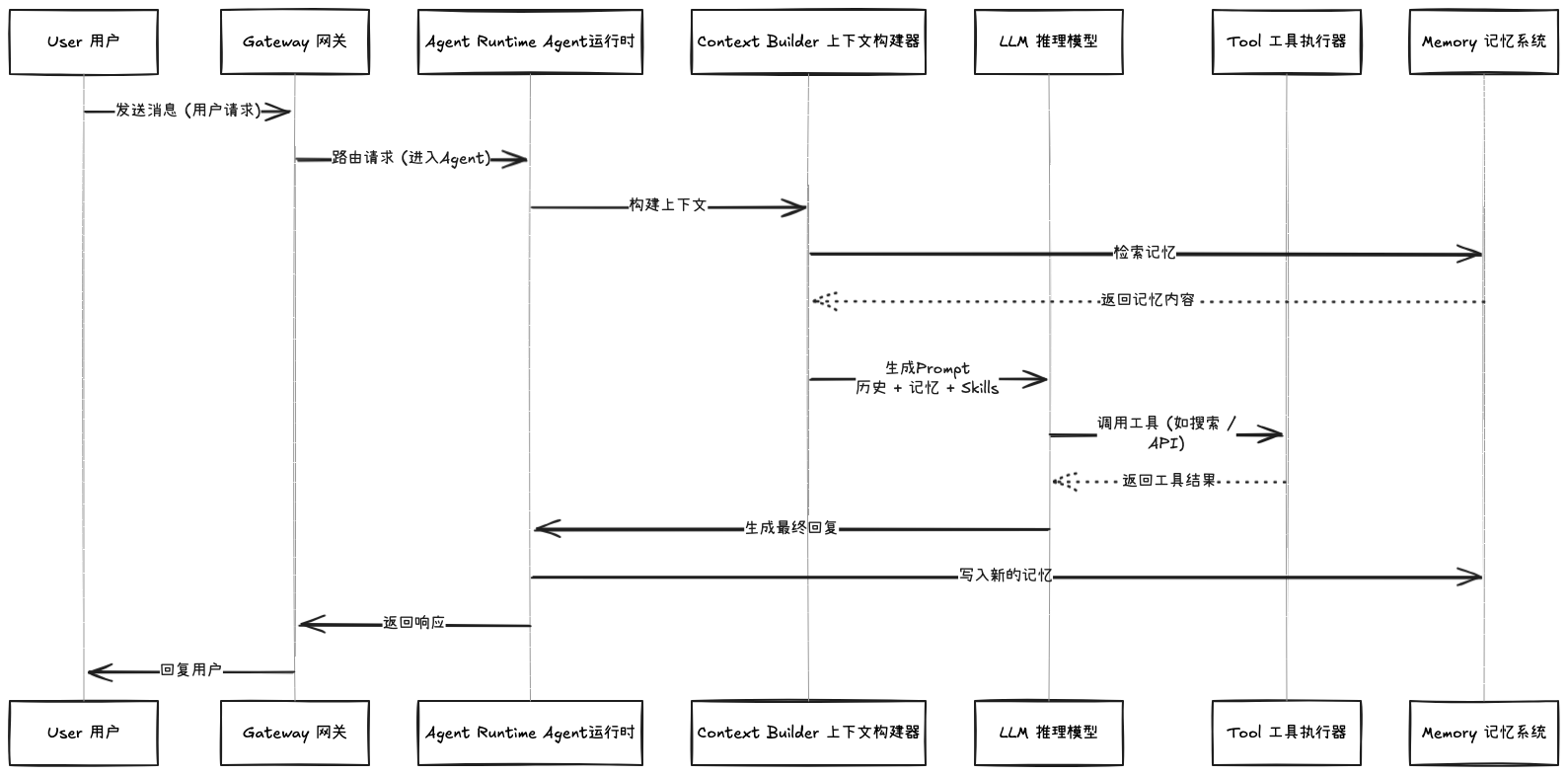
这是 OpenClaw 的核心,也是所有 AI Agent 的核心概念。官方文档这样描述:
Agentic Loop 是 Agent 的完整运行周期:接收输入 → 组装上下文 → 模型推理 → 执行工具 → 流式回复 → 持久化
我们一步步拆解。
1. 上下文组装
在大模型看到你的消息之前,Agent 运行时会组装一个"上下文包"。系统提示词由四部分构成:
OpenClaw 的基础提示词
Agent 始终遵循的核心指令
技能提示词
可用技能的简明列表(名称、描述、路径)
启动上下文文件
提供环境级别的上下文
单次运行覆盖
针对特定任务的额外指令
大模型没有眼睛,它只能看到你放进上下文窗口的东西。上下文组装不是可以跳过的预处理步骤,它是整个 Agent 系统中最重要的工程决策。模型知道什么、相信什么、能做什么,全都取决于这一步。
2. 模型推理
组装好的上下文被发送给你配置的模型提供商(Anthropic、OpenAI、Google、Ollama 等)。OpenClaw 会处理几个重要细节:
- 强制执行模型特定的上下文限制
- 保留压缩预留空间(一个 token 缓冲区),确保模型有足够空间回复
3. 工具执行——Agent"长出手脚"的地方
这是最有意思的部分。当大模型响应时,它会做两件事之一:
- 输出文本回复(这一轮结束)
- 请求工具调用(Tool Call)
工具调用是什么?就是模型用结构化格式输出:"我想运行这个特定工具,用这些特定参数。"比如"我需要读这个文件"或"我需要搜索网页"或"我需要发这封邮件"。
OpenClaw 的 Agent 运行时会拦截这个请求,执行工具,捕获结果,然后把结果作为新消息反馈回对话。模型看到结果后,决定下一步做什么——可能是再调用一个工具,也可能是最终写出回复。
这个循环叫 ReAct 循环(Reason 推理 + Act 行动)。这是 Agent 和聊天机器人的本质区别。
while True:
回复 = 大模型.调用(上下文)
if 回复.是文本():
发送回复(回复.文本)
break
if 回复.是工具调用():
结果 = 执行工具(回复.工具名, 回复.工具参数)
上下文.添加消息("工具结果", 结果)
OpenClaw 实现了同样的循环模式,而且是实时流式返回的。你能看到工具被调用,看到结果返回,看到模型基于结果进行推理,然后给出回复。
技能系统:按需加载的"专业知识"
OpenClaw 的技能(Skills)设计非常优雅,也是一个很好的提示词工程实践案例。
一个技能就是一个文件夹,里面有个 SKILL.md 文件。这个 Markdown 文件用自然语言写着指令、示例,有时还包括工具配置,告诉 Agent 怎么处理特定领域的任务——比如管理 GitHub 仓库、审查 PR、或者调用某个 API。
--- name: github-pr-reviewer description: 审查GitHub拉取请求并发布反馈 --- # GitHub PR审查员 当被要求审查拉取请求时: 1. 使用web_fetch工具从GitHub URL获取PR差异 2. 分析差异,检查正确性、安全问题和代码风格 3. 将审查结构化为:摘要、发现的问题、建议 4. 如果被要求发布审查,使用GitHub API工具提交 始终保持建设性。将阻塞性问题与建议分开标记。
关键来了:OpenClaw 不会把所有技能的完整文本都塞进系统提示词。相反,上下文组装步骤只注入一个简洁的技能列表——基本上就是名称、描述和文件路径。模型读到这个列表,当它判断某个技能与当前任务相关时,才会按需读取那个技能的 SKILL.md。
模型不是被动接收指令,而是主动决定查阅哪些技能,按需加载。上下文窗口是有限的,这种设计让基础提示词保持精简,无论你安装了多少技能。
技能可以从 ClawHub(OpenClaw 的社区注册表)安装,也可以自己写。
社区技能可能导致静默数据泄露和提示词注入式攻击。安装任何第三方技能前,务必审查代码,尤其是那些能访问邮件或浏览器自动化的技能。
MCP:标准化的工具层
一些 OpenClaw 部署集成了 MCP 服务器作为标准化工具层,把 Agent 连接到外部服务,比如 Google 日历、Notion、智能家居、或自定义 API。MCP 的原生支持在项目中还在积极演进,但社区适配器已经让它成为可能。
工具可移植性
为一个兼容 MCP 的 Agent 构建的工具,可以在其他说同样协议的系统中复用。
标准接口
Agent 永远不直接接触底层服务。它调用一个标准接口,MCP 服务器处理剩下的事。
记忆系统:让 AI 记住你是谁
问任何一个 AI 工程师,Agent 系统中最难的问题是什么,记忆肯定排在前几位。大模型本质上是无状态的,每次对话都从白纸开始。那怎么构建一个能记住你的偏好、正在进行的项目、沟通风格的 Agent,而且能跨越几天、几周?
OpenClaw 的答案刻意保持简单,我认为这是整个项目中最好的设计决策之一。
记忆就存在普通的 Markdown 文件里,放在 Agent 工作区,默认是 ~/.openclaw/workspace。OpenClaw 的配置和状态(凭证、会话、日志、已安装技能)存在 ~/.openclaw/ 下。
~/.openclaw/workspace/
+-- AGENTS.md <-- Agent配置和指令
+-- SOUL.md <-- 性格、偏好、语气
+-- MEMORY.md <-- 长期事实和摘要
+-- HEARTBEAT.md <-- 主动任务清单
+-- memory/
+-- 2026-02-15.md <-- 每日临时日志
+-- 2026-02-16.md <-- 每日临时日志
每日日志(memory/YYYY-MM-DD.md)是持久化的、只追加的文件,记录每天发生了什么。重要的是,这些不会在每一轮对话时自动注入上下文。Agent 通过记忆工具按需检索它们,只在与当前任务相关时才读取。这让日常对话保持精简,避免不必要的上下文膨胀。
- MEMORY.md 存储 Agent 了解到的关于你的长期事实:比如"用户喜欢简洁的回复"、"用户的技术栈是 Next.js 和 Supabase",或者"周五永远不要安排会议"。
- SOUL.md 定义 Agent 的性格、名字和沟通风格。这让它感觉像你的助手,而不是一个通用机器人。
当加载所有这些历史会超出上下文窗口时,OpenClaw 会运行压缩(Compaction)流程。它把较旧的对话轮次总结成压缩条目,保留语义内容的同时减少 token 数量。这是解决基于大模型系统中长上下文问题的实用方案。
对于记忆检索,OpenClaw 支持基于嵌入的搜索,可选地通过 sqlite-vec SQLite 扩展加速。根据配置,一些部署会将其与基于关键词的搜索配对,既能概念匹配,又能精确 token 匹配。
没有外部数据库。没有 Redis。没有 Pinecone。就是 SQLite 和 Markdown 文件。这很好地提醒我们:在工程中,能真正解决问题的最简单方案,通常就是正确的方案。
心跳机制:让 AI 主动干活
OpenClaw 有个很有意思的特性:它不只是坐在那儿等你发消息。它有个心跳(Heartbeat)机制:一个定时触发器,默认每 30 分钟触发一次。
每次心跳时,Agent 读取 HEARTBEAT.md,这是一个它应该主动检查的任务清单。它决定现在是否有事情需要注意。如果有,就采取行动,可能给你发条消息。如果没事,它回复 HEARTBEAT_OK,网关会抑制这个回复,不会发给你。
定时触发的 Agent 循环——不只是响应人类输入,Agent 会定期被唤醒,被要求评估它的任务列表。你可以用它每天给自己发简报、监控网站变化、或者在你注意到之前就发现日历冲突。
完整流程:一条消息的旅程
把所有这些拼起来,一条消息在 OpenClaw 中的完整流程是这样的:
- 消息到达 → 渠道适配器标准化
- 路由 → 网关决定哪个 Agent、哪个会话
- 排队 → 命令队列串行化执行
- 上下文组装 → 系统提示词 + 技能列表 + 记忆 + 历史
- 模型推理 → 调用大模型 API
- 工具执行 → ReAct 循环(可能多轮)
- 流式回复 → 实时返回给用户
- 持久化 → 更新会话历史和记忆文件
这告诉我们什么?
大多数现代 Agent 框架在不同的 API 和抽象下,共享着相同的核心模式。看 OpenClaw,你能清楚地看到它们:
OpenClaw 的价值不在于它独创了这些模式,而在于它让这些模式变得具体、基于文件、可读。你可以打开 SOUL.md 看到 Agent 遵循的确切指令。你可以读任何 SKILL.md 理解一个能力是怎么添加的。你可以检查 MEMORY.md 审计 Agent 知道的关于你的一切。
这种透明性既是它最大的工程优点,也是最大的安全攻击面。一个能访问你的文件、浏览器、邮件和聊天工具的 Agent 是强大的。一个恶意技能或者通过 Agent 访问的网页发起的提示词注入攻击,理论上可以危及所有这些。在把网关暴露到网络之前,务必运行安全审计工具,安装任何第三方技能前都要审查代码。
写在最后
OpenClaw 在 2026 年初成为 GitHub 上增长最快的仓库之一。开发者社区不只是在认可一个有用的工具,他们在认可一种架构模式。
本地网关 + Agent 循环 + 技能系统 + 持久化记忆——这个模式会在很长时间内成为个人 AI Agent 的蓝图。
如果你想真正理解 AI Agent 是怎么工作的,OpenClaw 是你能研究的最好的真实案例之一。代码是 MIT 开源的,架构是可读的,它实现的概念和严肃 AI 公司生产环境中的 Agent 系统是一样的。
去读源码。打开一个 SKILL.md。编辑你的 SOUL.md。搞坏点东西。这才是真正学习的方式。